

 hadoop client 설치와 HADOOP_CLASSPATH 잡기
hadoop client 설치와 HADOOP_CLASSPATH 잡기
하둡클러스터에 접근해서 파일을 확인하고 복사할때 하둡 클라이언트 바이너리를 설치해야한다. 보통 메이저버전만 맞추면 일반적으로 돌아가는 편인데 다음 경로에서 다운로드를 받아 압축을 푼다. https://hadoop.apache.org/releases.html 압축풀기화 설정복사 위 경로에서 다운로드를 받았다면, 다음과 같이 압축해제된 경로를 HADOOP_HOME 으로 경로를 잡아주고, core-site.xml, hdfs-site.xml 설정파일을 복사하면된다. (ambari에서 client 설정을 다운로드 받아서 복사하거나 하둡클러스터 서버에서 해당 설정을 가져와도 된다.) # 하둡 2.10.2 버전 다운로드 및 해제 (/home1/user/ 에서 다운받았다고 가정) $ wget https://dlcdn...
하둡클러스터에 kerberos 인증이 있다면, kinit 명령을 통해서 인증을 거친후 hadoop 명령어를 사용할 수 있다. 하지만, BashOperator 에서 매번 kinit 명령을 넣어서 DAG 를 구성하는건 꽤 번거로운일이다. 왜냐하면, 사용자가 암호를 생략하려면 keytab 파일을 사용해야 하는데 경로를 매번 기억해서 쓰는것도 번거롭다. 다행히 airflow 에서는 커버로스 인증을 주기적으로 하는 옵션이 존재한다. airflow kerberos 사용하기 우선 airflow.cfg 설정에 커버로스 관련 인증 설정이 필요하다. 당연히 인증을 위한 keytab 파일도 존재해야한다. [core] ... security = kerberos .... [kerberos] ccache = /tmp/airflo..
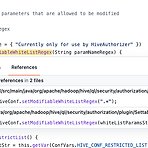 [Airflow] hive_operator 실행 오류 : Cannot modify airflow.ctx.xxx at runtime
[Airflow] hive_operator 실행 오류 : Cannot modify airflow.ctx.xxx at runtime
Airflow 에서 "hive_cli_default" Connection 을 설정할때, Extra 옵션에 {"use_beeline": true} 를 추가하면, beeline 을 통해 쿼리를 실행한다. 근데, 기본적으로 -hiveconf 옵션에 airflow.ctx.* 패턴의 값이 추가되면서 아래와 같은 오류가 발생될 때가 존재한다. java.lang.IllegalArgumentException: Cannot modify airflow.ctx.dag_id at runtime. It is not in list of params that are allowed to be modified at runtime 이 오류를 재현하는 방법은 beeline 을 실행할때 -hiveconf airflow.ctx.dag_id=..
airflow 에서 셀러리기반으로 운영할때 DAG 요청을 담는 메시지큐로 rabbitmq 를 주로 사용한다. 그런데 테스트를 위해 모든 노드를 죽였는데 rabbitmq 가 기동을 못하는 상황이 발생되었다. 로그를 확인해보면 다음과 같은 메시지가 error 메시지로 존재했었다. Feature flag 'quorum_queue': migration function crashed Jul 12 18:24:03 my-server001 rabbitmq-server[48802]: * suggestion: start the node Jul 12 18:24:03 my-server001 rabbitmq-server[48802]: rabbit@my-server002: Jul 12 18:24:03 my-server001 ra..
커버로스 인증은 성공했는데, 하둡에서 명령을 실행했을때 다음과 같이 "javax.security.sasl.SaslException: GSS initiate failed" 오류가 날때가 있다. 이 문제를 해결하려면 $JAVA_HOME 하위의 security 파일에 krb5.conf 설정을 복사하면 해결된다. $ kinit product Password for product@MY-DOMAIN.BAR.COM: $ hadoop fs -ls / 2022-05-10 18:55:12,732 WARN security.UserGroupInformation: Not attempting to re-login since the last re-login was attempted less than 60 seconds before..
하둡에 인증을 넣어 관리할때 커버로스 인증을 사용해서 권한 관리를 할때는 hadoop 명령어를 이용해서 접근할 경우 다음과 같이 오류가 발생된다. 그래서 하둡명령을 날리기전에 kinit 명령을 실행해서 인증을 거친이후 하둡명령을 실행해야 사용이 가능하다. $ hadoop fs -ls ls: failure to login: using ticket cache file: FILE:/tmp/krb5cc_p13321 javax.security.auth.login.LoginException: java.lang.IllegalArgumentException: Illegal principal name foo@BAR.COM: org.apache.hadoop.security.authentication.util.Kerbero..
 [FLINK] Avro 포맷에서 TO_TIMESTAMP_LTZ 사용시 정밀도 오류
[FLINK] Avro 포맷에서 TO_TIMESTAMP_LTZ 사용시 정밀도 오류
Flink 에서 Window 단위로 데이터를 다루려면 워터마크를 지정해야하고, 워터마크를 지정하기위해서 TO_TIMESTAMP_LTZ 함수를 써서 날짜타입으로 전환해서 사용해야 하는 경우가 종종 있다. 보통 EpochTime 이 들어있는 필드를 쓴다면 아래와 같은 형태로 워터마크를 선언하려고 할것이다. CREATE TABLE source_table { ... rowtime AS TO_TIMESTAMP_LTZ(logTime, 6), // logTime 의 단위는 microsec WATERMARK FOR rowtime AS rowtime } WITH { ... }; 그리고, 원본의 logTime 필드의 값이 microsec 이라서 정밀도값을 6으로 지정하면 다음과 같은 오류가 발생한다. org.apache...
데이터를 다루기 위해서는 다양한 데이터 변환과 조작작업을 주기적으로 수행해야 한다. 이런 행위를 단단히 줄여서 ETL (Extract, Transform, Load) 작업이라고 하는데, 이런 작업을 구성하고 스케쥴 하는 방법에 대해서는 몇년전엔 여러 플랫폼들이 혼재되어있었지만 지금은 AIRFLOW 가 결국 살아 남은거 같다. 과거에는 춘추전국 시대 사실 ETL 을 전문적으로 다루지 않는 부서에서는 Jenkins(젠킨스) 와 Spring Batch(스트림배치) 를 섞어서 주기적인 배치작업을 돌리는 경우도 많다. (Jenkins 는 빌드관리를 위한 용도인데, 희안하게 주위에 배치 스케쥴러로 쓰는 케이스를 꽤 많이 봤다) crontab 을 쓰는것 대비 WEB UI 에서 진행상태나 로그를 확인 할 수 있기 때문..