
티스토리 뷰
Kafka 의 토픽에 있는 데이터를 실시간성으로 데이터 집계 하기위해서는 Kafka Streams 를 많이 사용한다.
사용하기도 쉬운편이고, 카프카에만 의존되다보니 사실상 카프카만 세팅되어있다면 바로 활용가능하다.
하지만, 스트림 처리에서는 배치에는 없는 개념이 많다보니 의도하지 않은 형태로 결과가 나올때 가 많다.
결과가 반복되는 현상
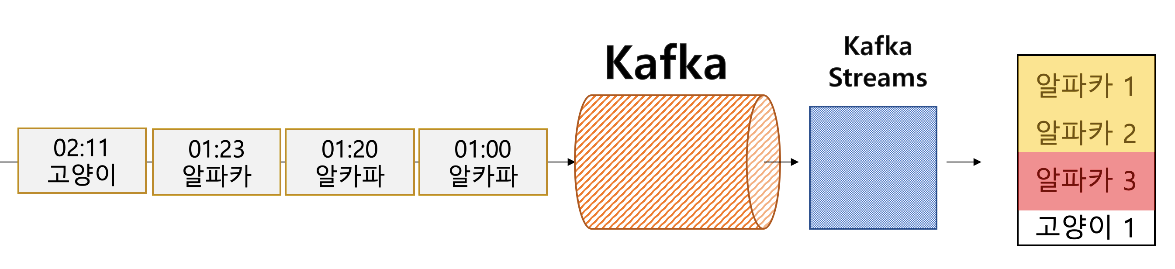
스트림데이터는 무한의 데이터이다. 그래서 분석을 위해 어떤 시간기준으로 잘라서 집계를 하고 이걸 저장해서 분석하는게 일반적이다.
예를 들어, 1시간 윈도우로 단어 갯수를 샌다고 할때 나는 01:00~02:00 의 최종결과인 알파카 3(붉은색) 결과만 출력하고 싶은데, 중간 합계 결과인 (알파카 1), (알파카2) 가 같이 나오는 문제가 골치아픈 경우가 있다.
왜냐면, KafkaStreams 로 선집계하고 그 결과를 hive 에 저장한다고 치면 이런 중복결과는 필요없기 때문이다.
어떻게 해결할까?
commit.interval.ms 를 길게 설정해도 비슷한 효과를 볼 수 있긴 하겠지만 타이밍이 어긋날수 있다.
해결방법은 reduce 선언후 suppress 를 선언하고, window가 close 될때까지 출력을 지연시키는 형태로 사용하면 된다.
그러면, 위에서 노란색친 중간 결과가 출력되지 않고, 다음 시간대의 로그가 올때 flush 된다고 생각하면 편하다.
// suppress 를 선언하고, window 가 close 되는 시점으로 지연시키면됨
inputData
.map(aggregate)
.groupByKey(Grouped.with(Serdes.String(), GsonSerde(AdRecordMetric::class.java)))
.windowedBy(TimeWindows.of(Duration.ofMinutes(60)).grace(Duration.ZERO) )
.reduce(..생략...)
.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded())) // <- 요거
.toStream()그리고 덤으로 윈도우크기를 지정할때, TimeWindows.of(윈도우크기) 만 선언하면, grace()의 기본값이 너무 커서 결과가 안나오는것처럼 보일때가 있다. 이때는 위와같이 grace() 의 값을 0 으로 지정하거나 적절한 시간을 지정해서 테스트 하면된다.
grace 에 정의하는 값은 뭔지 궁금할텐데... 쉽게 생각해서, 지각생 로그를 얼마나 기다려 줄것인가? 하는 값이다.
왜냐면, 데이터가 async 하게 들어오고 네트워크나 여러 문제로 카프카의 토픽에 저장될때 시간순서가 안지켜 질수 있다.
그래서 윈도우가 종료되는 시점을 유도리(?) 있게 버퍼를 둬서 판단을 보류한다는것이다.
이 부분은 파티션이 여러개일때 집계 결과가 이빠지는 경우를 설명할때 좀더 보충설명 하도록 하겠다.
'데이터처리 > Kafka' 카테고리의 다른 글
| [팁] SCRAM-SHA-512 인증 있는 카프카에 명령어 실행하는 방법 (2) | 2021.11.18 |
|---|---|
| 카프카 토픽결과 조회 방법 (confluent AVRO format) - 예시 - (0) | 2021.11.17 |
| [추천] Kafka 명령어 유틸리티 소개 - kafkactl (실무자가 강추) (1) | 2021.11.01 |
| Kafka 의 용어 이해하기 - 토픽, 스키마레지스트리 (0) | 2021.10.18 |