
티스토리 뷰
Hive 에서 쿼리를 돌리다보면, 특정 리듀서 하나에서 작업이 안끝나고 무한정 대기하는 경우가 종종있다.
이런 경우 skewed 형태의 데이터구조일 확률이 높다. skewed 라는건 데이터가 균일하지 않고, 특정 key 에 데이터가 쏠려있음을 의미한다. 특정 리듀서에 데이터가 쏠려있어서 병목이 되는 현상이다. (이미지에서 1개의 task 만 끝나지 않는 상황인걸 보면 쉽게 이해 할수 있다)
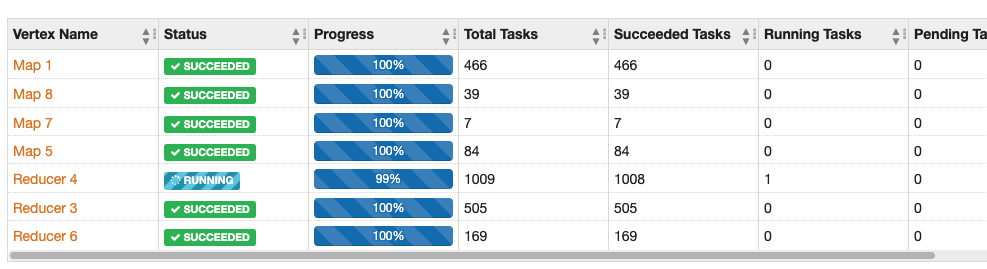
Skewed 데이터 문제
이런 데이터 쏠림현상은 생각보다 흔하다. 우리나라 성씨만 봐도 "김씨" 가 압도적으로 많다. 아마 ㄱㄴㄷ 형태로 담당자를 정하면 ㄱ을 담당한 사람은 숫자 카운팅할때 엄~~청 오래걸릴수 밖에 없을것이다. 이런 문제를 해결하려면 데이터 쏠림이 심한 테이터를 분산처리할 수 있도록 유도해주어야 한다. hive 에서는 skew에 관련된 옵션이 몇가지 존재한다.

튜닝방법
reducer 가 실행되는건 보통 aggregate 혹은 join 처리를 할때 필요하다. 그래서 두가지 방법에 따라 관련된 옵션이 다르다.
절대적인 수치가 있는게 아니고 데이터의 특성이나 규모에 따라 세밀한 수치는 조정을 해보아야 한다.
skew join 문제일때
아래와 같은 옵션이 영향을 받는다. skew 의 문제는 데이터는 많은데 분산이 적절하게 되지 않은게 문제이므로, 쏠림현상이 있는 데이터를 적절한 크기로 잘라서 분산처리 하게 유도되면 된다. 그래서 활성화 여부와 skewjoin 의 여부를 판단할수 있는 기준값을 설정으로 지정하여 해결할수 있다.
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=500000;
set hive.skewjoin.mapjoin.map.tasks=10000;
set hive.skewjoin.mapjoin.min.split=33554432;이와 관련해 더 궁금하면 아래 링크를 참고하도록 하자.
https://medium.com/expedia-group-tech/skew-join-optimization-in-hive-b66a1f4cc6ba
skew aggregate / group by 문제일때
참고로 아래 수치는 절대적인 수치는 아니고, 참고를 위한 값을 넣어둔것이다.
데이터 쏠림이 있을때 자동으로 로드밸런싱을 하도록 유도하는것과, 리듀서에 보내기전에 map 단계에서 중간 집계를 하는것을 활성화 하는 형태로 개선하는 방법이 있다. (map/reduce 에서 combiner 를 사용하는것과 비슷한 효과로 보임)
---------------------
-- 데이터 쏠림에 대한 로드밸런싱 여부
---------------------
set hive.groupby.skewindata=true;
---------------------
-- map 에서 부분집계 유도
---------------------
set hive.map.aggr=true;
set hive.groupby.mapaggr.checkinterval=100000;
set hive.map.aggr.hash.min.reduction=0.5;그룹바이의 skewed 데이터문제는 중국 사이트이긴한데 여기가 가장 잘 정리된거 같으니 참고하도록 하자
https://zhuanlan.zhihu.com/p/345770553
'데이터처리 > Hive' 카테고리의 다른 글
| [Hive] select * from table 에서 필드 일부만 제외하는 방법? - 블랙리스트 방식 (0) | 2022.10.25 |
|---|---|
| [HIVE] distinct count 문제 해결 및 튜닝방법 정리 (0) | 2022.06.08 |
| [오류] hive 를 union all 할때 null 오류 문제 -tez엔진- (0) | 2021.11.23 |
| [오류] hive llap 지원 버전 오류 - java.lang.OutOfMemoryError: Java heap space - 컨테이너모드 (0) | 2021.11.22 |
| [튜닝] Hive 에서 Broadcast Join 을 이용한 join 성능 튜닝방법 (0) | 2021.11.21 |